Reversing lists¶
The goal of this lecture note is to describe how to reverse lists and the ensuing programming pattern of using accumulators.
Resources¶
- The OCaml code for the present lecture note (latest version: 05 Apr 2020).
Reversing a list¶
Reversing a list means listing its elements in reverse order:
let test_reverse candidate =
let b0 = (candidate [] = [])
and b1 = (candidate [0] = [0])
and b2 = (candidate [1; 0] = [0; 1])
and b3 = (candidate [2; 1; 0] = [0; 1; 2])
(* etc. *)
in b0 && b1 && b2 && b3;;
Besides, list reversal is obviously involutory, i.e., applying it twice in a row to a list yields back this list. More ammunition for our unit-test function:
let test_reverse candidate =
let b0 = (candidate [] = [])
and b1 = (candidate [0] = [0])
and b2 = (candidate [1; 0] = [0; 1])
and b3 = (candidate [2; 1; 0] = [0; 1; 2])
and b4 = (let ns = atoi 100
in candidate (candidate ns) = ns)
(* etc. *)
in b0 && b1 && b2 && b3 && b4;;
OCaml offers a predefined function, List.rev, that does the job:
# test_reverse List.rev;;
- : bool = true
#
Writing a function reverse that, given a list, returns its converse requires some thought, however. Indeed OCaml lists are constructed by starting from the empty list, and successively adding elements in front of the list that has been constructed so far. Take the list [2; 1; 0], for example, as constructed by atoi. It is a traditional linked list with one forward link and no back link. Pictorially:
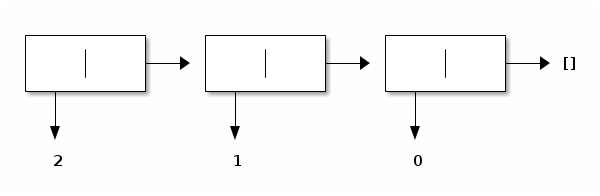
This list is constructed starting from the empty list, by adding 0 in front, and then by adding 1 in front, and then by adding 2 in front:
# [];;
- : 'a list = []
# 0 :: [];;
- : int list = [0]
# 1 :: 0 :: [];;
- : int list = [1; 0]
# 2 :: 1 :: 0 :: [];;
- : int list = [2; 1; 0]
#
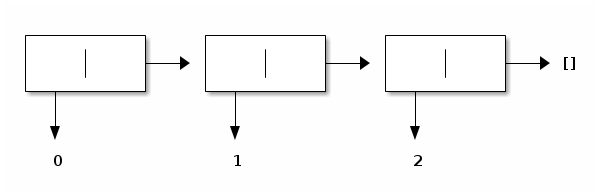
Symmetrically, its converse is [0; 1; 2]. It is constructed starting from the empty list, by adding 2 in front, and then by adding 1 in front, and then by adding 0 in front:
# [];;
- : 'a list = []
# 2 :: [];;
- : int list = [2]
# 1 :: 2 :: [];;
- : int list = [1; 2]
# 0 :: 1 :: 2 :: [];;
- : int list = [0; 1; 2]
#
Pictorially:
The challenge for writing a function reverse lies in the very nature of the one list constructor and the two list accessors: List.cons, List.hd, and List.tl all operate at the beginning of a list. However, the elements at the beginning of the input list occur at the end of the output list, and vice versa.
Reversing a list, Version 1: the first shall be the last¶
Fortunately, a modicum of recursive thinking solves the problem:
reversing the empty list yields the empty list; and
reversing a non-empty list will require combining its head with the result of reversing its tail (which is the induction hypothesis).
Let us revisit the example of the list [2; 1; 0]. Its head is 2 and its tail is [1; 0]. Reversing its tail yields [0; 1]. Our problem is as follows: given 2 and [0; 1], how do we obtain [0; 1; 2]? The List.append function springs to the mind: we could apply it to [0; 1] and to ...? And to ...? It can’t be to 2 since List.append expects both of its parameters to be lists. So let us make a singleton list out of 2 (i.e., a list that only contains one element) and apply List.append to [0; 1] and to this singleton list, [2]: the result is [0; 1; 2], as desired.
In OCaml:
let reverse_v1 vs_init =
let rec visit vs =
if vs = []
then []
else let ih = visit (List.tl vs)
in List.append ih [List.hd vs]
in visit vs_init;;
Let us run it through the unit test:
# test_reverse reverse_v1;;
- : bool = true
#
Success.
Food for thought:
Consider the successive calls to visit in reverse_v1 and visualize them when reverse_v1 is applied to the list [1; 2; 3; 4; 5]:
# traced_reverse_v1 [1; 2; 3; 4; 5];; visit [1; 2; 3; 4; 5] -> tl [1; 2; 3; 4; 5] -> tl [1; 2; 3; 4; 5] <- [2; 3; 4; 5] visit [2; 3; 4; 5] -> tl [2; 3; 4; 5] -> tl [2; 3; 4; 5] <- [3; 4; 5] visit [3; 4; 5] -> tl [3; 4; 5] -> tl [3; 4; 5] <- [4; 5] visit [4; 5] -> tl [4; 5] -> tl [4; 5] <- [5] visit [5] -> tl [5] -> tl [5] <- [] visit [] -> visit [] <- [] hd [5] -> hd [5] <- 5 append [] [5] -> append [] [5] <- [5] visit [5] <- [5] hd [4; 5] -> hd [4; 5] <- 4 append [5] [4] -> append [] [4] -> append [] [4] <- [4] append [5] [4] <- [5; 4] visit [4; 5] <- [5; 4] hd [3; 4; 5] -> hd [3; 4; 5] <- 3 append [5; 4] [3] -> append [4] [3] -> append [] [3] -> append [] [3] <- [3] append [4] [3] <- [4; 3] append [5; 4] [3] <- [5; 4; 3] visit [3; 4; 5] <- [5; 4; 3] hd [2; 3; 4; 5] -> hd [2; 3; 4; 5] <- 2 append [5; 4; 3] [2] -> append [4; 3] [2] -> append [3] [2] -> append [] [2] -> append [] [2] <- [2] append [3] [2] <- [3; 2] append [4; 3] [2] <- [4; 3; 2] append [5; 4; 3] [2] <- [5; 4; 3; 2] visit [2; 3; 4; 5] <- [5; 4; 3; 2] hd [1; 2; 3; 4; 5] -> hd [1; 2; 3; 4; 5] <- 1 append [5; 4; 3; 2] [1] -> append [4; 3; 2] [1] -> append [3; 2] [1] -> append [2] [1] -> append [] [1] -> append [] [1] <- [1] append [2] [1] <- [2; 1] append [3; 2] [1] <- [3; 2; 1] append [4; 3; 2] [1] <- [4; 3; 2; 1] append [5; 4; 3; 2] [1] <- [5; 4; 3; 2; 1] visit [1; 2; 3; 4; 5] <- [5; 4; 3; 2; 1] - : int list = [5; 4; 3; 2; 1] #See how, at call time, visit is applied to the successive suffixes of [1; 2; 3; 4; 5] and how, at return time, visit returns the successive prefixes of [5; 4; 3; 2; 1]?
Both the time and space complexity of List.hd and List.tl are constant. Both the time complexity and the space complexity of List.append are linear on its first argument, since List.append prepends its first argument (i.e., copies it) in front of its second argument.
Therefore, at return time, the lists [], [5], [5; 4], ..., and [5; 4; 3; 2; 1] will be successively copied, which corresponds to copying 0 + 1 + 2 + ... + 5 list elements, or again 5 * 6 / 2 elements, or again a number of elements that is proportional to the square of 5.
So both the time complexity and the space complexity of reverse_v1 are quadratic. That doesn’t feel right because the size of the output is the same as the size of the input. Shouldn’t the complexity of reversing a list be linear (i.e., proportional to the length of this list) rather than quadratic (i.e., proportional to the square of this length)?
Reversing a list, Version 2: the last shall be the first¶
Just as plausibly, however, we could assume two functions hd_op and tl_op that are converses of List.hd and List.tl:
whereas applying List.hd to a non-empty list returns the first element of that list, applying hd_op to a non-empty list would return its last element; and
whereas applying List.tl to a non-empty list returns [the list of] all the elements of that list except the first (i.e., its longest strict suffix), applying tl_op to a non-empty list would return [the list of] all the elements of that list, except the last (i.e., its longest strict prefix):
let test_hd_op candidate = let b0 = (0 = candidate [0]) and b1 = (0 = candidate [1; 0]) and b2 = (0 = candidate [2; 1; 0]) and b3 = (0 = candidate [5; 4; 3; 2; 1; 0]) (* etc. *) in b0 && b1 && b2 && b3;; let test_tl_op candidate = let b0 = (candidate [0] = []) and b1 = (candidate [1; 0] = [1]) and b2 = (candidate [2; 1; 0] = [2; 1]) and b3 = (candidate [5; 4; 3; 2; 1; 0] = [5; 4; 3; 2; 1]) (* etc. *) in b0 && b1 && b2 && b3;;
Given a non-empty list, hd_op traverses it in search of its last element and returns it, and tl_op copies it in the same order up to and excluding the last element and returns the resulting first strict prefix:
let hd_op vs_init =
let rec visit v vs =
match vs with
| [] ->
v
| v' :: vs' ->
visit v' vs'
in match vs_init with
| [] ->
assert false
| v :: vs' ->
visit v vs';;
let tl_op vs_init =
let rec visit v vs =
match vs with
| [] -> []
| v' :: vs' ->
let ih = visit v' vs'
in v :: ih
in match vs_init with
| [] ->
assert false
| v :: vs' ->
visit v vs';;
As a sanity check, let us run them through their unit test:
# test_hd_op hd_op;;
- : bool = true
# test_tl_op tl_op;;
- : bool = true
#
Using hd_op and tl_op, writing reverse is straightforwardly done using structural recursion. In the induction case, to reverse a non-empty list, we cons its last element to the result of reversing its first strict suffix:
let reverse_v2 vs_init =
let rec visit vs =
if vs = []
then []
else (hd_op vs) :: (visit (tl_op vs))
in visit vs_init;;
Let us run it through the unit test:
# test_reverse reverse_v2;;
- : bool = true
#
Success.
Food for thought:
What would reverse_v2 compute if hd_op is replaced by List.hd and tl by List.tl?
Consider the successive calls to visit in reverse_v2 and visualize them when reverse_v2 is applied to the list [1; 2; 3; 4; 5]:
# traced_reverse_v2 [1; 2; 3; 4; 5];; visit [1; 2; 3; 4; 5] -> hd_op [1; 2; 3; 4; 5] -> hd_op [2; 3; 4; 5] -> hd_op [3; 4; 5] -> hd_op [4; 5] -> hd_op [5] -> hd_op [1; 2; 3; 4; 5] <- 5 tl_op [1; 2; 3; 4; 5] -> tl_op [2; 3; 4; 5] -> tl_op [3; 4; 5] -> tl_op [4; 5] -> tl_op [5] -> tl_op [5] <- [] tl_op [4; 5] <- [4] tl_op [3; 4; 5] <- [3; 4] tl_op [2; 3; 4; 5] <- [2; 3; 4] tl_op [1; 2; 3; 4; 5] <- [1; 2; 3; 4] visit [1; 2; 3; 4] -> hd_op [1; 2; 3; 4] -> hd_op [2; 3; 4] -> hd_op [3; 4] -> hd_op [4] -> hd_op [1; 2; 3; 4] <- 4 tl_op [1; 2; 3; 4] -> tl_op [2; 3; 4] -> tl_op [3; 4] -> tl_op [4] -> tl_op [4] <- [] tl_op [3; 4] <- [3] tl_op [2; 3; 4] <- [2; 3] tl_op [1; 2; 3; 4] <- [1; 2; 3] visit [1; 2; 3] -> hd_op [1; 2; 3] -> hd_op [2; 3] -> hd_op [3] -> hd_op [1; 2; 3] <- 3 tl_op [1; 2; 3] -> tl_op [2; 3] -> tl_op [3] -> tl_op [3] <- [] tl_op [2; 3] <- [2] tl_op [1; 2; 3] <- [1; 2] visit [1; 2] -> hd_op [1; 2] -> hd_op [2] -> hd_op [1; 2] <- 2 tl_op [1; 2] -> tl_op [2] -> tl_op [2] <- [] tl_op [1; 2] <- [1] visit [1] -> hd_op [1] -> hd_op [1] <- 1 tl_op [1] -> tl_op [1] <- [] visit [] -> visit [] <- [] visit [1] <- [1] visit [1; 2] <- [2; 1] visit [1; 2; 3] <- [3; 2; 1] visit [1; 2; 3; 4] <- [4; 3; 2; 1] visit [1; 2; 3; 4; 5] <- [5; 4; 3; 2; 1] - : int list = [5; 4; 3; 2; 1] #See how, at call time, visit is applied to the successive prefixes of [1; 2; 3; 4; 5] and how, at return time, visit returns the successive suffixes of [5; 4; 3; 2; 1]?
Both the time and space complexity of List.cons are constant. The time complexity of hd_op is linear on its argument, and its space complexity is constant. Both the time complexity and the space complexity of tl_op are linear on its argument.
Therefore, both at call time and at return time, visit will incur a cost that is linearly proportional to the length of its argument. If the input of reverse_v2 has length 5, the overall cost of using visit is linearly proportional to 5 + 4 + 3 + 2 + 1 + 0, or again 5 * 6 / 2, which is a number proportional to the square of 5.
So both the time complexity and the space complexity of reverse_v2 are quadratic. Again, that doesn’t feel right because the size of the output is the same as the size of the input. Again, shouldn’t the complexity of reversing a list be linear rather than quadratic?
Reversing a list, Version 3: trading space for time¶
Common to Versions 1 and 2 of reverse is the successive copying of all the elements but the last one either of the input list (Version 2, with tl_op) or of the result of the recursive calls (Version 1, with List.append). We could trade space for time with an index, using List.nth to pick the successive elements of the list in reverse order:
let reverse_v3 vs_init =
let rec visit i =
if i = 0
then []
else let i' = i - 1
in let ih = visit i'
in (List.nth vs_init i') :: ih
in visit (List.length vs_init);;
This version passes the unit test:
# test_reverse reverse_v3;;
- : bool = true
#
Food for thought:
Consider the successive calls to visit in reverse_v3 and visualize them when reverse_v3 is applied to the list [1; 2; 3; 4; 5]:
# traced_reverse_v3 [1; 2; 3; 4; 5];; length [1; 2; 3; 4; 5] -> length [2; 3; 4; 5] -> length [3; 4; 5] -> length [4; 5] -> length [5] -> length [] -> length [] <- 0 length [5] <- 1 length [4; 5] <- 2 length [3; 4; 5] <- 3 length [2; 3; 4; 5] <- 4 length [1; 2; 3; 4; 5] <- 5 visit 5 -> visit 4 -> visit 3 -> visit 2 -> visit 1 -> visit 0 -> visit 0 <- [] list_nth [1; 2; 3; 4; 5] 0 -> list_nth [1; 2; 3; 4; 5] 0 <- 1 visit 1 <- [1] list_nth [1; 2; 3; 4; 5] 1 -> list_nth [2; 3; 4; 5] 0 -> list_nth [1; 2; 3; 4; 5] 1 <- 2 visit 2 <- [2; 1] list_nth [1; 2; 3; 4; 5] 2 -> list_nth [2; 3; 4; 5] 1 -> list_nth [3; 4; 5] 0 -> list_nth [1; 2; 3; 4; 5] 2 <- 3 visit 3 <- [3; 2; 1] list_nth [1; 2; 3; 4; 5] 3 -> list_nth [2; 3; 4; 5] 2 -> list_nth [3; 4; 5] 1 -> list_nth [4; 5] 0 -> list_nth [1; 2; 3; 4; 5] 3 <- 4 visit 4 <- [4; 3; 2; 1] list_nth [1; 2; 3; 4; 5] 4 -> list_nth [2; 3; 4; 5] 3 -> list_nth [3; 4; 5] 2 -> list_nth [4; 5] 1 -> list_nth [5] 0 -> list_nth [1; 2; 3; 4; 5] 4 <- 5 visit 5 <- [5; 4; 3; 2; 1] - : int list = [5; 4; 3; 2; 1] #See how, at call time, the index decreases all the way to 0 and how, at return time, visit returns the successive suffixes of [5; 4; 3; 2; 1]?
In contrast to the two first versions, this version only uses List.cons to construct the result, and since the complexity of List.cons is constant, the space complexity of reverse_v3 is linear. (Yay.)
Still, for a list of length n, reverse_v3
- traverses the list with n tail calls to compute its length;
- traverses the list with n-1 tail calls to access its nth element;
- traverses the list with n-2 tail calls to access its (n-1)th element;
- ...
- traverses the list with 2 tail calls to access its 3rd element;
- traverses the list with 1 tail call to access its 2nd element; and
- traverses the list with 0 tail calls to access its 1st element.
All in all, given a list of length n, reverse_v3 makes n + n-1 + n-2 + ... + 2 + 1 + 0 tail calls, i.e., its time complexity is quadratic.
So while the space complexity of reverse_v3 is linear, its time complexity is quadratic. That doesn’t feel quite right either because why should we need a quadratic time complexity to perform a computation whose space complexity is linear?
Reversing a list, Version 4: using an accumulator¶
We have not been thinking right about list reversal:
- the first element of the input list is the first element that will be consed [to the empty list] to construct the result;
- the second element of the input list is the second element that will be consed to construct the result;
- the third element of the input list is the third element that will be consed to construct the result;
- etc.
We should exploit this coincidence by synchronizing the traversal of the input list and the construction of the output list. To this end, let us add a second argument to the local function that traverses the input list and let us accumulate the output list over this second argument during the traversal:
let reverse_v4 vs_init =
let rec visit vs a =
if vs = []
then a
else visit (List.tl vs) (List.hd vs :: a)
in visit vs_init [];;
This version passes the unit test:
# test_reverse reverse_v4;;
- : bool = true
#
Food for thought:
Consider the successive calls to visit in reverse_v4 and visualize them when reverse_v4 is applied to the list [1; 2; 3; 4; 5]:
# traced_reverse_v4 [1; 2; 3; 4; 5];; visit [1; 2; 3; 4; 5] [] -> visit [2; 3; 4; 5] [1] -> visit [3; 4; 5] [2; 1] -> visit [4; 5] [3; 2; 1] -> visit [5] [4; 3; 2; 1] -> visit [] [5; 4; 3; 2; 1] -> visit [1; 2; 3; 4; 5] [] <- [5; 4; 3; 2; 1] - : int list = [5; 4; 3; 2; 1] #
- Observe how all calls are tail calls and therefore there is only one return time? This version is iterative: it implements a loop.
- Observe the synchronicity, at call time, between incrementally traversing the input and constructing the output.
- Observe the invariants in the successive calls to visit:
- the first actual parameter enumerates the successive suffixes of the given list (denoted by vs_init), from this given list all the way to the empty list;
- the second actual parameter enumerates the successive reversed prefixes of the given list, from the empty list all the way to the final result;
- at every call, concatenating the reverse of the second actual parameter and the first actual parameter yields the given list;
- at every call, concatenating the reverse of the first actual parameter and the second actual parameter yields the resulting list.
In contrast to the three first versions, this version only uses List.cons, List.hd, and List.tl, whose time complexity and space complexity are constant. Therefore both the time complexity and space complexity of reverse_v4 are linear.
The extra argument for visit is called an accumulator, and as it happens, it is not only useful to reverse a list – far from it, as developed in the next lecture note.
Exercise 0¶
Summarize the key points of the sections above (Versions 1 to 4). What are the pros and cons of each of the reverse functions?
Exercise 1¶
Given the standard definitions of List.append (to concatenate two lists), List.rev (to reverse a list), and List.map (to map a function over a list, homomorphically), consider the following 10 functions:
- fun xs ys -> List.append (List.reverse xs) (List.reverse ys)
- fun xs ys -> List.append (List.reverse ys) (List.reverse xs)
- fun xs ys -> List.reverse (List.append ys xs)
- fun xs ys -> List.reverse (List.append xs ys)
- fun f xs -> List.map f (List.reverse xs)
- fun f xs -> List.reverse (List.map f (List.reverse xs))
- fun f xs -> List.reverse (List.map f xs)
- fun f xs -> List.map f xs
- fun f xs ys -> List.map f (List.append xs ys)
- fun f xs ys -> List.append (List.map f xs) (List.map f ys)
Which of these functions are equivalent for given functions that are pure? Briefly justify each answer.
Resources¶
- The OCaml code for the present lecture note (latest version: 05 Apr 2020).
Version¶
Fine-tuned traced_reverse_v2 and traced_reverse_v3 [05 Apr 2020]
Streamlined the unit-test functions [08 Jun 2019]
Created [17 Mar 2019]